A call stack is used for several related purposes, but the main reason for having one is to keep track of the point to which each active subroutine should return control when it finishes executing. An active subroutine is one that has been called but is yet to complete execution after which control should be handed back to the point of call. Such activations of subroutines may be nested to any level (recursive as a special case), hence the stack structure. If, for example, a subroutine DrawSquare calls a subroutine DrawLine from four different places, DrawLine must know where to return when its execution completes. To accomplish this, the address following the call instruction, the return address, is pushed onto the call stack with each call.
Description
Since the call stack is organized as a stack, the caller pushes the return address onto the stack, and the called subroutine, when it finishes, pulls or pops the return address off the call stack and transfers control to that address. If a called subroutine calls on yet another subroutine, it will push another return address onto the call stack, and so on, with the information stacking up and unstacking as the program dictates. If the pushing consumes all of the space allocated for the call stack, an error called a stack overflow occurs, generally causing the program to crash. Adding a subroutine's entry to the call stack is sometimes called "winding"; conversely, removing entries is "unwinding".
There is usually exactly one call stack associated with a running program (or more accurately, with each task or thread of a process), although additional stacks may be created for signal handling or cooperative multitasking (as with setcontext). Since there is only one in this important context, it can be referred to as the stack (implicitly, "of the task"); however, in the Forth programming language the data stack or parameter stack is accessed more explicitly than the call stack and is commonly referred to as the stack (see below).
In high-level programming languages, the specifics of the call stack are usually hidden from the programmer. They are given access only to a set of functions, and not the memory on the stack itself. This is an example of abstraction. Most assembly languages, on the other hand, require programmers to be involved with manipulating the stack. The actual details of the stack in a programming language depend upon the compiler, operating system, and the available instruction set.
Functions of the call stack
As noted above, the primary purpose of a call stack is to store the return addresses. When a subroutine is called, the location (address) of the instruction at which it can later resume needs to be saved somewhere. Using a stack to save the return address has important advantages over alternative calling conventions. One is that each task can have its own stack, and thus the subroutine can be reentrant, that is, can be active simultaneously for different tasks doing different things. Another benefit is that recursion is automatically supported. When a function calls itself recursively, a return address needs to be stored for each activation of the function so that it can later be used to return from the function activation. Stack structures provide this capability automatically.
Depending on the language, operating-system, and machine environment, a call stack may serve additional purposes, including for example:
Local data storage
A subroutine frequently needs memory space for storing the values of local variables, the variables that are known only within the active subroutine and do not retain values after it returns. It is often convenient to allocate space for this use by simply moving the top of the stack by enough to provide the space. This is very fast when compared to dynamic memory allocation, which uses the heap space. Note that each separate activation of a subroutine gets its own separate space in the stack for locals.
Parameter passing
Subroutines often require that values for parameters be supplied to them by the code which calls them, and it is not uncommon that space for these parameters may be laid out in the call stack. Generally if there are only a few small parameters, processor registers will be used to pass the values, but if there are more parameters than can be handled this way, memory space will be needed. The call stack works well as a place for these parameters, especially since each call to a subroutine, which will have differing values for parameters, will be given separate space on the call stack for those values.
Evaluation stack
Operands for arithmetic or logical operations are most often placed into registers and operated on there. However, in some situations the operands may be stacked up to an arbitrary depth, which means something more than registers must be used (this is the case of register spilling). The stack of such operands, rather like that in an RPN calculator, is called an evaluation stack, and may occupy space in the call stack.
Pointer to current instance
Some object-oriented languages (e.g., C++), store the this pointer along with function arguments in the call stack when invoking methods. The this pointer points to the object instance associated with the method to be invoked.
Structure
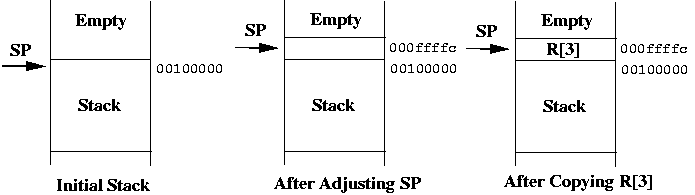
SP (Stack pointer) 是一个专用的寄存器,用来保存栈的栈顶地址。所有低于 SP 地址的数据都是 Garbage,等于 SP 地址以及高于 SP 地址所存储的数据都是合法的数据。 Stack bottom 是整个栈可以使用的最大的地址,当这个栈初始化的时候 SP 指向栈底。 Stack limit 是整个栈最小的地址,当 SP 比 stack limit 更小的时候,栈就溢出了。
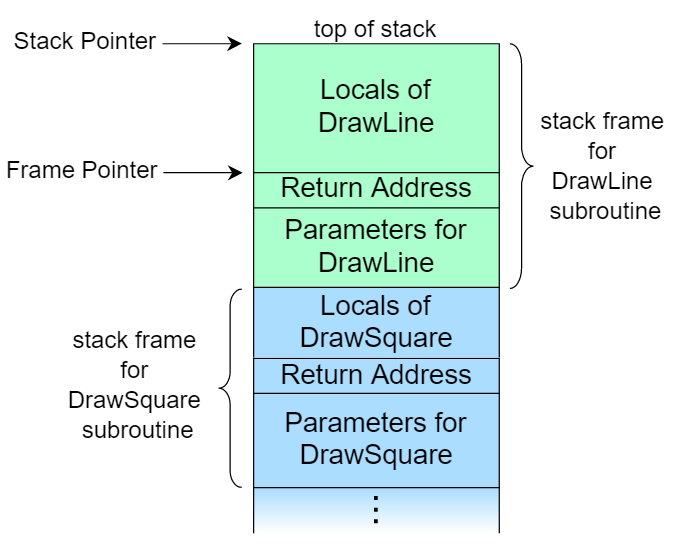
当一个函数被调用的时候,会分配一块栈空间给函数,叫做(栈帧) stack frame,直到函数调用完成,栈帧被回收。
Stack frame: 栈帧相当于一个函数的运行环境,它包括本地变量,函数参数,返回值等等。
Previous frame 指的是 foo1 的栈帧,Current frame 指的是 foo2 的栈帧。同时会有一个新的寄存器 FP (Frame pointer) 存储调用者(这里是 foo1)FP 的地址。通过向高地址或者低地址偏移 FP,foo2 可以读取到输入参数以及本地变量。
创建 foo2 栈帧的过程应该是这样的:先往 foo1 栈帧中压入 foo2 需要接受的参数(输入参数),再压入 return address,指的是结束调用 foo2 之后应该调用的指令的地址。随后创建 foo2 的栈帧压入本地变量等等。
一旦 foo2 调用结束,foo2 的栈帧被弹出整个调用栈,随后将 FP 恢复至调用者(foo1)的 FP,SP 指向 foo1 的 return address(此时的栈顶),执行下一条指令。