使用 HTTP Methods 构建 RESTful API
HTTP Methods 一共有九个,分别是 GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS,CONNECT,PATCH。在RESTful API 设计中,常用的有POST,GET,PUT,PATCH 和 DELETE,分别对应对资源的创建,获取,修改,部分修改和删除操作。下表简单列出了这些Methods的用途和返回值约定。
1 API 命名应该采用约定俗成的方式,保持简洁明了
所有 API 应该使用 REST 架构约定形式命名。REST架构的思想是将 API 请求对象看成一个个资源,实现者使用相应的 HTTP 的动词(GET, POST, PUT, PATCH, DELETE)来访问和操作这些资源。
- GET /users 获取所有用户
- GET /users/1234 获取ID为1234的用户
- POST /users 创建一个新用户
- PUT /users/1234 更新ID为1234的用户
- PATCH /users/1234 更新ID为1234的用户的部分内容
- DELETE /users/1234 删除ID为1234的用户
您可能已经注意到了,以上 API 中资源命名都使用了复数的形式。这是一个约定,它可以省去设计时考虑数据具体细节的麻烦(数据是复数还是单数?)。现在大很多常见的系统都使用了复数形式。比如Twitter 的 REST APIs 和 Facebook 的 Graph API 基本都是复数形式。
然而实际系统一般都不可能只有单一资源,资源和资源之间有各种关系是很正常的情况,那么如何设计存在关联资源(数据)的API呢?
如果要设计一个资源拥有另外一个资源的情况的API,例如,设计一个包含用户(users)和用户的评论(comments)的 API 可以采用这样的形式:
- GET /users/1234/comments 获取用户ID为1234的所有评论
- GET /users/1234/comments/1 获取用户ID为1234的评论ID为1的单个评论
- DELETE /users/1234/messages/1 删除用户评论ID为1,属于用户1234的单个评论
当然,如果一个资源并不依附其它资源而可以独立存在,是没有必要这样设计的,完全可以使用和 users 一样的形式提供,如果要查询其中的关系,可以使用其它资源作为 ID 的形式来过滤。例如 /comments?user_id=1234。关于这点详细内容可以参见下面的第三条“优雅的设计条件过滤,排序,搜索和限制返回数据的参数形式”。
上述设计原则都是使用 HTTP Method,会不会有超出 HTTP Method 表达语义的 API 呢?答案是肯定的。实际工程实践中往往会遇到并不是对一个资源简单的 CRUD 的场景,设计此类 API 有这些手法可供参考:
将这些操作变成一个资源的属性,比如 disable 一个 user,可以在 user 里面加一个 disabled 的属性,可以设计一个 API 使用 PATCH /users/1234 将 disabled 设置成 true 即可。
将这个操作看成某个资源的附属资源(就像上面例子中的 comments 一样)来设计,比如GitHub的Star a gist API ,就是这样的,它把star操作放在这个资源的后面,看上去好像是一个附属资源:
- PUT /gists/:id/star - DELETE /gists/:id/star在不得不使用其它例外形式设计 API 时,尽量用文档写清楚输入输出和返回值等其他必要信息,避免让习惯了使用资源名的调用者感到困惑。 例如,如果要设计一个 API 用来根据输入关键词返回搜索结果,搜索结果可能有 user,可能有 comments,或者二者都有,这种情况下,我们很难按照约定的资源形式设计API。我们可以使用 GET /search 这样的形式设计 API,但是最好给出文档说明,说明输入和输出细节。
2.考虑到系统迭代和兼容性,需要在 API 中引入版本规则
现代系统的迭代速度一般都很快,设计优良的 API 版本规则可以给持续集成和系统升级带来便利,降低因系统迭代引发的问题。在升级到新版 API 到同时,可以选择依然支持旧版本 API 一段时间,这样可以给其它客户端和子系统一个缓冲时间,让其有充分的时间升级和适配新版本的API。
关于设置API的版本信息,常见的有两种方法,一种是将版本号放在 http header 内,另一种是直接放在 URL 中。而放在 URL 中是最常见的做法,比如:
- GET https://api.twitter.com/1.1/friends
- GET "https://graph.facebook.com/v2.8/me
其中1.1 和v2.8就是API的版本号,这种做法的好处是简单易读,不容易混淆。 为了简单起见,可以省略最新的 API 版本号,假设v3.0是最新版本,调用下面的API应该返回相同的结果:
- /api/users/1234
- /api/v3.0/users/1234
- /v3/users/1234
如果一个 API 的版本过期了,任何把该请求重定向到最新版本上。比如 user API v1 版本过期了,当有调用/api/v1.0/users/1234的时候,应该被重定向(http 30x)到最新的 /api/v2.0/users/1234 上。
3 优雅的设计条件过滤,排序,搜索等传入参数形式
RESTful API 经常有对返回数据过滤和排序的要求,这些输入参数推荐采用 HTTP Query Parameter 的方式实现。
比如你要设计一个API,返回所有已经登录的用户,可以这样做:
GET /users?login=true获取所有的用户,返回结果按照create_at降序排序可以这样设计:
GET /users?sort=-create_at当然也可以组合使用过滤条件和排序:
GET /users?sort=-create_at,login_at&login=true 表示返回所有已登录用户,结果按照create_at降序, login_at升序有些时候你可以单独为 API 设计一个 Query Parameter 专门用于搜索。这样特别适用你的后端在使用了ElasticSearch 或者其它如 Lucene,Solr之类的搜索引擎架构,因为从 API 中传递过来的 Query Parameter 可以直接设置成这些搜索框架的输入条件。这种情况的API可以这样设计:
GET /users?q=key&&sort=-create_at,login_at&diabled=false对于一些常用的条件搜索和过滤,可以考虑映射到一个新的API(相当于快捷方式)比如设计一个用于返回最近登录用户的API:
GET /users/recently_login
这种设计可以简化客户端的调用,否则调用者每次都要根据时间合成 Query Parameter,增加了客户端使用复杂度。
查询数据的部分内容
有些时候资源属性很多(比如 user 包含 name, address, email, phone...),不同的客户端需要的内容不尽相同(有的客户端可能只需要name, address),如果一股脑的全部返回,尤其在数据量比较大情况下会对带宽带来不必要的浪费。我们可以采用这样的形式来过滤数据的属性:
GET /user?fields=id,user_name,address&diabled=false&sort=-login_at GET /facebook/v2.8/me?fields=id,name,birthday,cover,devices,email&access_token=xxx
您可以已经注意到了上述API中都使用了下划线(user_name)的形式来命名这些参数。作为程序员你一定会争论是使用划线(user_name)还是使用驼峰(userName)的形式呢?
这个问题一直没有一个明确的答案。一般要求所有 API 保持风格一致即可。从个人接触的一些常见系统 API 来看,使用下划线的方式居多。值得提到的是有项研究表明,使用下划线分割的形式比使用驼峰的形式更容易阅读(容易20%),如果从可读性方面来说应该使用下划线的方式来分隔是个不错的选择。
4.合理设计返回数据的形式,格式和考虑启用压缩
GET 操作的返回数据是显而易见,这里不做过多讨论。对于更新和创建操作(PUT POST PATCH),API 在执行相关的操作之后要把更新后的数据也做为返回值的一部分返回给调用者,这样可以避免调用者再次调用 GET API 来获取更新,而浪费一次 HTTP 请求。特别是对于 POST 操作的 API,因为该 API 会创建数据,该数据被创建后的唯一性 ID 往往由服务端生成,如果不返回新创建的 ID,客户端就不能基于这个数据做进一步操作。这个部分理论基础可以参见RESTful Web Service 架构剖析 - 6.2 Resource Identifiers。
举个例子来说明这个情况: 假如有个系统提供一个 API 用于上传一张图,这张图上传之后你可以调用另外一个 API 修改这个图片的描述。如果调用上传 API 后,返回数据中没有返回这张图的唯一性 ID,你就无法接着调用其它 API 引用到这个图的资源,从而无法进行修改描述的操作,除非之前额外再次调用查询操作拉取到这张图唯一性 ID。
通常,POST 操作成功以后,我们一般也把新创建的资源的 URL 放在 HTTP header 的 location 字段中,方便客户的拉取。例如上上树图片上传的 API 返回的 header 中可以包含 location:http://api.domain.name/photos/1234
对于返回数据,另一个值得一提的是使用gzip,这点虽然和 AP I设计本身无关,只是服务器配置上的问题,之所以特别提出,是因为 RESTful API 一般都是返回文本数据,启用 gzip 通常可以节省60%-80%以上的带宽(这个数据很好证明,随便使用几个个 json 文件 gzip下就可以看出来,我测试几个 json 文件一般300K左右都能被压缩成50K左右),尤其是在返回的数据比较大情况下,压缩比更高。不过启用gzip 不可避免会增加 CPU 的负担,实际工程项目中需要权衡考量。
至于到底用什么用的格式来返回数据?XML?JSON?纯文本?但从统计数据来看 JSON 格式目前是使用做多的 REST API 的输入输出格式。
有些系统设计采用 application/x-www-form-urlencoded 形式作为输入内容(以key=value&key=value...的形式 POST 去服务端,其中value使用urlencode)。这样设计优点是由于 value 内容是纯文本,可用自由的定义成各种其它系统方便解析的格式,使得服务端在解析 model 的上获取更大的自由度。此外 JAVA 的一个流行框架 Spring MVC controller 中可以直接使用@RequestParam用一个函数参数自动对应上 form post 过来的数据,省去了解析body中 JSON 的麻烦。
个人更倾向使用 JSON, 因为现在几乎主流的平台和语言都对 JSON 有着稳定高效的支持,各种简单易用的解析和生成 JOSN 的框架层出不穷,所以建议对于输入输出统一使用 JSON 格式(其中输入是指 POST, PUT & PATCH API 中放在 http body 中的输入参数)。
5.根据不同的 API 操作,设置合适的 HTTP 状态码和必要的出错信息
使用合理的状态码有助于提高客户端的易用性,因为这些 HTTP 状态代码本身就有一定的含义,如能在 API 返回信息中合理的利用,可以减少额外的文档描述,让API返回结果“不言自明”。
http status code 的常用应用场景如下:
- 200 OK 用于返回 GET, PUT, PATCH 或 DELETE 的操作。有使用也用来返回没有创建数据的 POST 操作;
- 201 Created 用来返回 POST 操作并且成功创建了数据的情况。新创建的数据资源的链接应该放在location中返回,具体参见这里 ;
- 204 No Content 用来返回一次成功的请求,但是该请求返回的 body 为空的情况,如 DELETE 请求;
- 304 Not Modified 表示缓存没有失效,和上次的请求相比,没有新的内容;
- 400 Bad Request 用于返回 API 参数不正确的情况,比如传入的 JSON 格式错误无法解析等;
- 401 Unauthorized 用于表示请求等 API 缺少身份验证信息;
- 403 Forbidden 用于表示该资源不允许特定用户访问;
- 404 Not Found 请求一个不存在的资源;
- 429 Too Many Requests 请求过于频繁,可以用在客户端调用过于频繁的情况。
对于需要提供额外说明的错误类型,可以在 HTTP Body 中详细描述,便于调用者排查原因。
{
"error": {
"message":"Message describing the error",
"type":"OAuthException",
"code":190,
"error_subcode":460,
"error_user_title":"A title",
"error_user_msg":"A message",
"fbtrace_id":"EJplcsCHuLu"
}
}
错误信息要容易解析,比如上面的错误信息中,返回的 JSON 数据下有个 error 属性,客户端只要判断属性是否存在即可判断是否有详细的错误信息。 如果你的API比较复杂,最好能有文档按照 error code 分门别类记录这些 error 产生的原因以及如何应对。
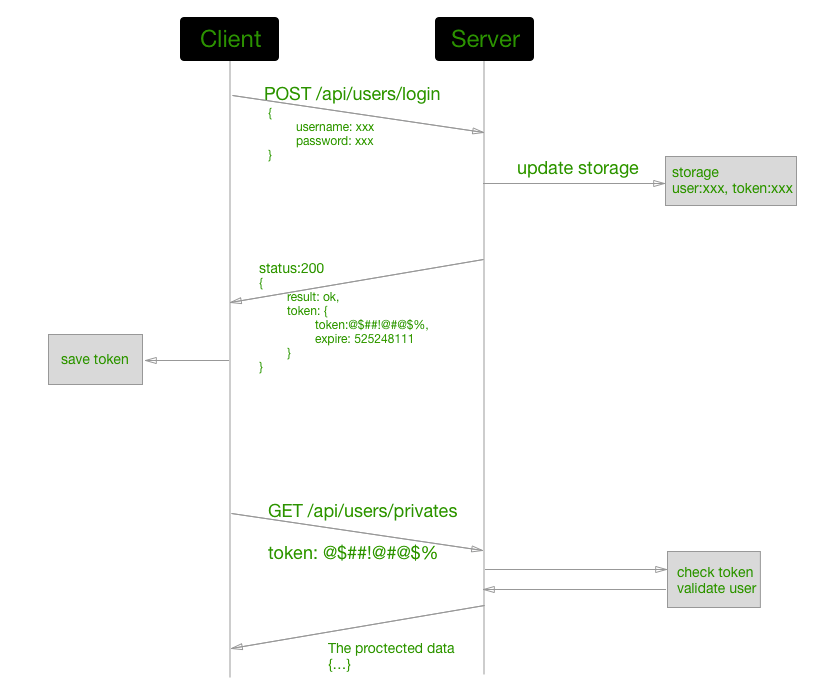
6.使用 token 机制设计鉴权和验证系统(Authorization and Authentication[1])
这个话题可以讨论的内容有很多,这里主要从实用的角度来给出一些解决方案和解决问题的思路。 由于 RESTful API 的无状态的特性,所以我们不能依赖请求前后的上下文来做鉴权和用户验证,那到底该如何区分调用者是谁从而确定它有没有相应的权限调用某个API?
我们先来看个例子,这个例子来自腾讯云微视频MVS API: 你在成功申请腾讯云的微视频服务之后会给你分配 Appid、Secret ID 之类的信息。客户端在调用上传和删除视频之类的 API 时, 需要把一个 token 放在 API 请求的 http header 的 Authorization 字段中。其中 token 是按照某种规则拼接 Appid、Secret ID 生成的。这样服务端在收到这个调用请求时就可以区分这个 API 是哪个用户调用的,该用户是否有相应的权限(其中 Appid 相当于用户名,Secret ID 相当于密码,应当妥善保存)。
这种设计思想很简单,原理就是:针对特定用户生成一个 token,之后每次API的调用请求都带上这个 token。为了防止 token 泄露引发的安全问题,还应该考虑 token 什么时候失效,什么时候需要重新生成。说到这里,可能会有人会问,为什么不实施OAuth 2?答案是适用场景不同,部署 OAuth2 也会将问题复杂化。OAuth 2 适合需要把某一资源暴露给第三方应用的情况,比如新浪微博提供 OAuth 2 验证,如果你使用新浪微博登录豆瓣,在你的同意下(你在微博的登录界面输入用户名密码,并且确认),微博最终会给豆瓣一个具有实效性的 token,豆瓣凭借这个 token 来读取你的昵称和头像信息。想想,如果不使用token,豆瓣只有知道你的用户名密码才能读取昵称和头像信息,这也是OAuth 2 要解决的一个问题。
在实际工程实践中,常见的场景就是用户系统。那么到底如何设计一个 API 能够针对不同的用户做出鉴权和验证?结合 OAuth2,参考上面腾讯云微视频MVS API的例子,这里给出一个实用的解决方案:
- 用户使用户名密码或者第三方登录,最终请求一个我们设计的登录 API(这个 API 接受用户名密码,或第三方登录验证结果);
- 服务端认证成功以后,生成一个 token,并将这个 token 和用户信息关联在一起,同时返回这个 token 给调用客户端; 客户端记录并保存下这个 token;
- 下次客户端发起和用户相关请求 API 都要在 http header 中带上这个 token;
- 服务端通过这个 token 去区分用户是谁,判断这个用户是否已经登录和有什么样的权限;
- 服务端也要考虑 token 的失效时间;
- 客户端在发现 token 失效的时候重新请求新的 token
7.如何实现数据的分页返回
通常情况下一次API调用不可能返回该资源的所有数据,因为,一来多数情况下一个资源包含的数据太多,二来客户端也没有必要一次使用所有数据,因为用户短时间上根本就看不了那么多内容,完全可以在需要的时候加载更多。
RESTful API 一般有两种形式的设计,一种是使用类似 Facebook Graph API 的方法,它把分页信息和数据一起返回,调用者只需要再次请求 next 中 URL 就可以获取下一页的数据,这种方式优点是灵活和直观,可以随意添加和分页相关的其他属性,例如总记录数,总页数等等。其中cursors用来解决“流”的问题(由于数据是动态增加的,基于旧数据的页数和页码会失效,于是引入 cursors 来标记数据位置,关于这个问题,Twitter 在介绍其timeline API时有图文并貌的详细描述)。
// Facebook Graph API paging
{
"data":[{...},{...}],
"paging": {
"cursors":{ "after":"MTAxNTExOTQ1MjAwNzI5NDE=", "before":"NDMyNzQyODI3OTQw" },
"previous":"https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next":"https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
另一种符合WEB标准的做法是使用 link header,简单来说就是在 http header 使用 link字段,提供一个和超链接一样目的 URL 地址,来实现不同资源之间的转跳。如GitHub的Api文档是这样规定分页信息的
Link: <https://api.github.com/user/repos?page=3&per_page=100>; rel="next",
<https://api.github.com/user/repos?page=50&per_page=100>; rel="last"
这种做法缺点是不太直观,如果使用 Postman 之类工具调试的时候,需要手动找到header中的内容复制出来才能发出下一页的请求。而第一种实现,直接点击这个链接即可。但第二种实现的优点是不会干扰数据,返回内容都是数据本身,无需在数据上嵌入额外的属性来说明分页信息,简单干净。至于如何选择,完全要看个人偏好和具体使用场景了。
8.如何处理有关联资源的返回数据
考虑这么一个情况:有一个 API,输入一个指定用户 id,返回一个该用户所有评论信息。最终要在 UI 上显示的,除了该用户评论的具体文本内容以外,还有用户名,头像,个人简介之类和该用户相关的详细信息。该API的返回值应该如何设计?
对客户端来说,最直观和容易处理的返回形式如下:
{
data: [
{user_id: "1234", avatar: "a.jpg", nick_name:"Jeffrey", comment:"RESTful Service API"},
{user_id: "1234", avatar: "a.jpg", nick_name:"Jeffrey", comment:"J:"}
...
]
}
你肯定一眼就能看出问题,是的,返回数据中 avatar 和 name 是每条数据都是重复的,所以你也可以这样设计返回数据: 先返回该用户的所有评论 /comments?user=1234
{
data: [
{user_id: "1234", comment:"RESTful Service API"},
{user_id: "1234", comment:"J:"},
. ..
]
}
9.考虑启用 HTTP 缓存机制
HTTP协议本身支持两种缓存机制: ETag 和 Last-Modified。由于这部分内容更多属于服务器配置范畴,这里只做简单介绍:
- ETag:HTTP 请求中在 header 中包含一个内容的 hash,如果返回结果没有变化,该请求会直接返回304 Not Modified,而不是所有数据内容本身
- Last-Modified: 和 Etag 工作原理差不多,只是使用时间戳作为内容是否过期的标志。 需要自己配制 WEB Server 的同学可以自行搜寻相关内容,如果你使用Nginx,可以参考这里: A Guide to Caching with NGINX and NGINX Plus。
10.限制 API 调用频次(Rate limiting )
出于防止恶意访问和服务器性能压力考虑,限制 API 访问频次是非常有必要的,尤其对于大型系统而言。如果一个客户端请求 API 的频率太快,根据HTTP协议,可以返回429 Too Many Requests。
如果要为客户端提供更加详细的调用频次和访问次数之类的信息,除了提供文档说明以外,还可以在 http header 用自定义字段的形式提供,比如 Twitter API 是这样做的:
- X-Rate-Limit-Limit: 该请求的调用上限
- X-Rate-Limit-Remaining: 15分钟内还可以调用多少次
- X-Rate-Limit-Reset: 还有多少秒之后访问限制会被重置
我们可以根据具体需求在 http header 中使用类似的形式,提供对API调用频率和访问限制的相关信息。当然,文档记录也是一个不错的选择,前提是你能保持文档和代码同步更新。
11.尽可能的使用 HTTPS,涉及用户验证的 API 一定要强制启用 HTTPS
在阅读第六章“使用 token 机制设计鉴权和验证”时,可能已经有读者感到 RESTful API 如果通过 HTTP 明文传递会有很大的安全问题。如果用于鉴权的 app id 和 Secret,甚至是用户名密码通过明文传递,那么它们很容易被截获和保存,完全没有安全性可言。
所以凡是涉及任何和用户特定信息相关内容 API 都要通过 HTTPS 暴露给调用者。事实上,你的 AP I应该全部使用 HTTPS。HTTPS 现在已经是各种网络服务的标配(比如 Xcode 默认不允许请求不安全的 HTTP 信息)
顺便提下,如果你的WEB Server 是 Nginx,在部署了 HTTPS 的情况下,下面两个选项务必仔细设置,因为这个两个简单的设置可以很大程度上避免一些安全问题:
ssl_prefer_server_ciphers: 表示服务端加密算法优先于客户端加密算法,主要是防止降级攻击 (downgrade attack)。 Strict-Transport-Security(HSTS):告诉浏览器这个域名在指定的时间(max-age)内应该强制使用 HTTPS 访问。