1 Design a web crawler
- 首先把网络抽象一个无向图,网页为节点.
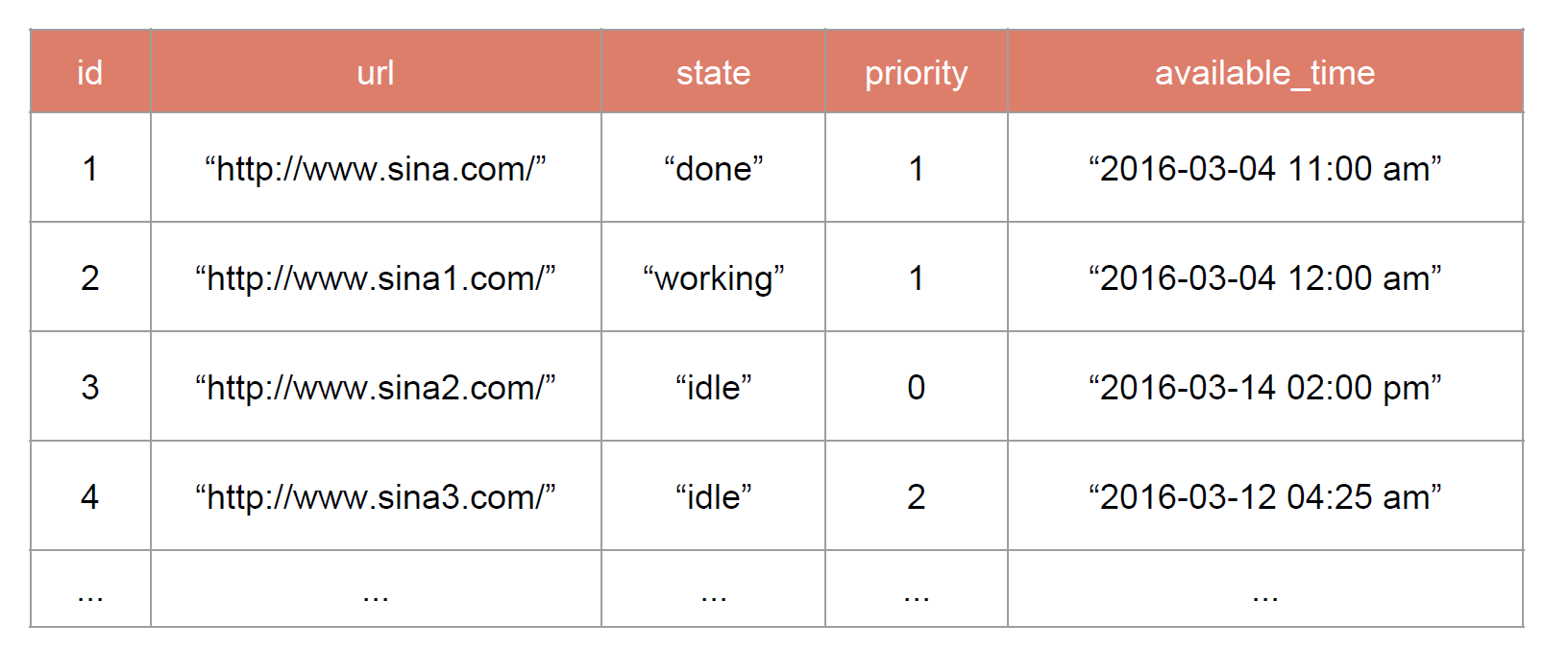
- 抓取算法, BFS, 可以根据Priority 做优化
- 网络模型, 可以利用服务器空闲时间,来异步抓取数据,减少线程切换所造成的消耗
- 对于一些新闻网页,做Count 过滤
- 根据网页的更新信息来判断下一次
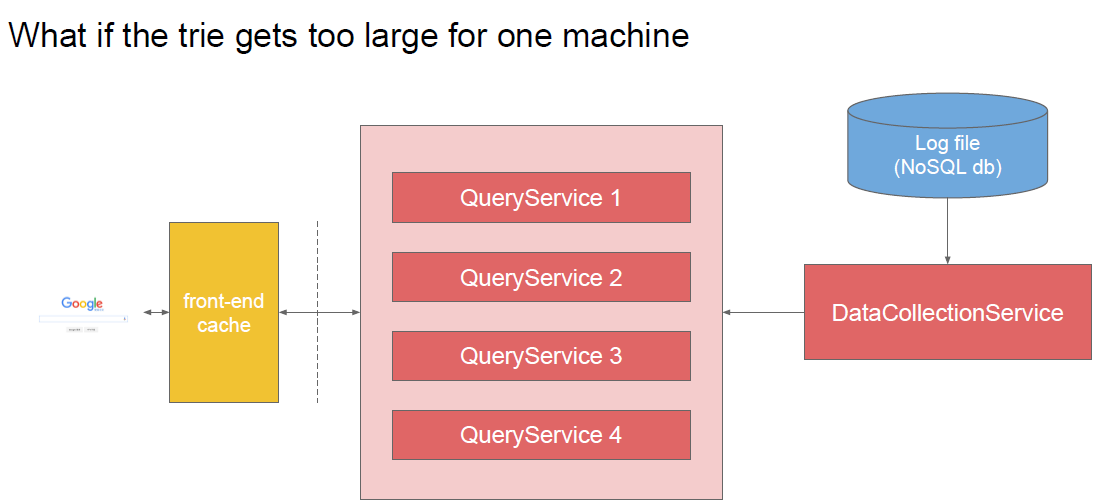
Needs: How many web pages? how long? how large?
- crawl 1.6m web pages per second
○ 1 trillion web pages
○ crawl all of them every week
- 10p (petabyte) web page storage
○ average size of a web page: 10k


Regular Expression
<h3[^>]*><a[^>]*>(.*?)<\/a><\/h3>
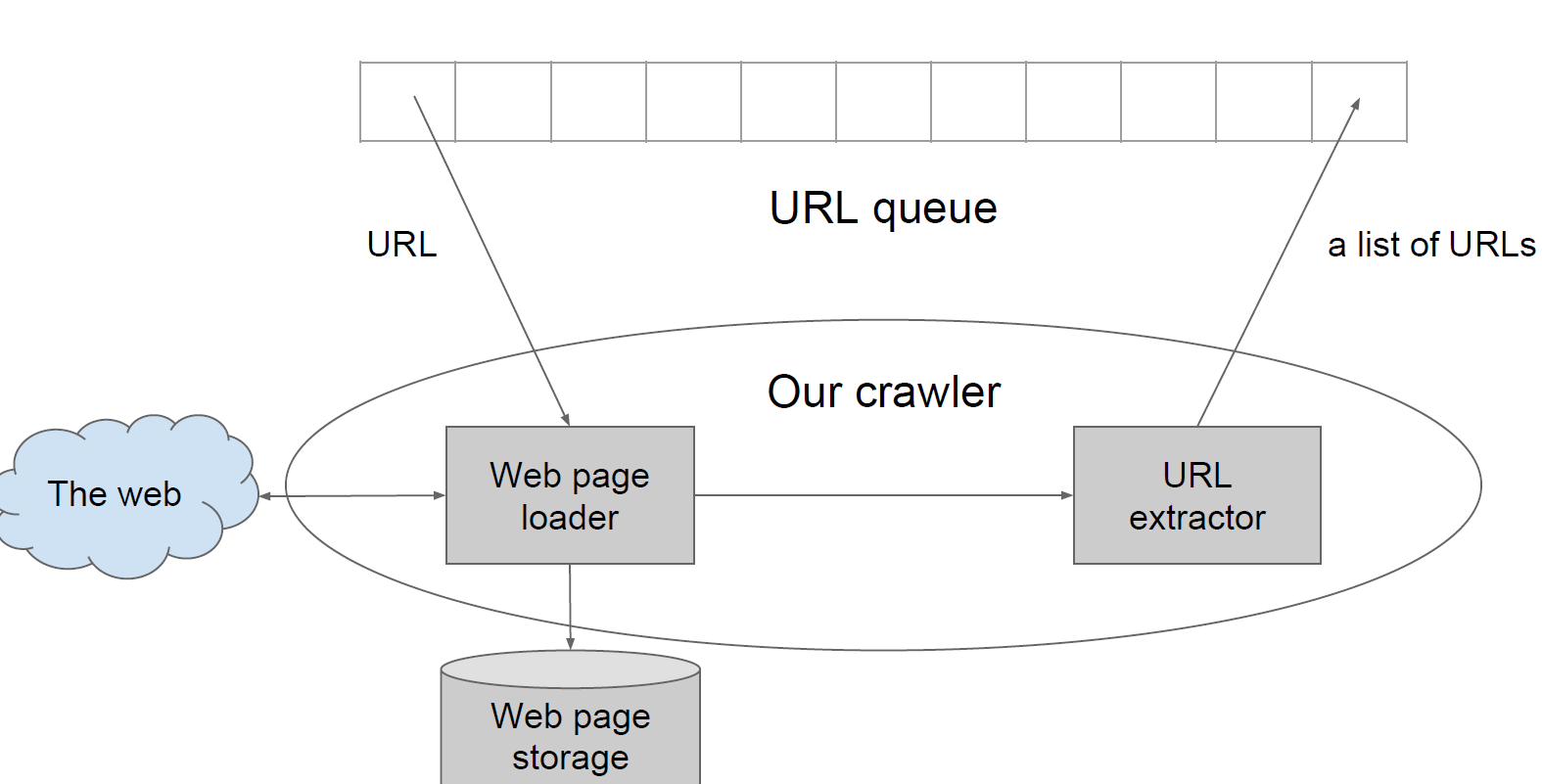
Use producer and cosumer parttern
Can use a blockingQueue to implment that.
2 Inverted index

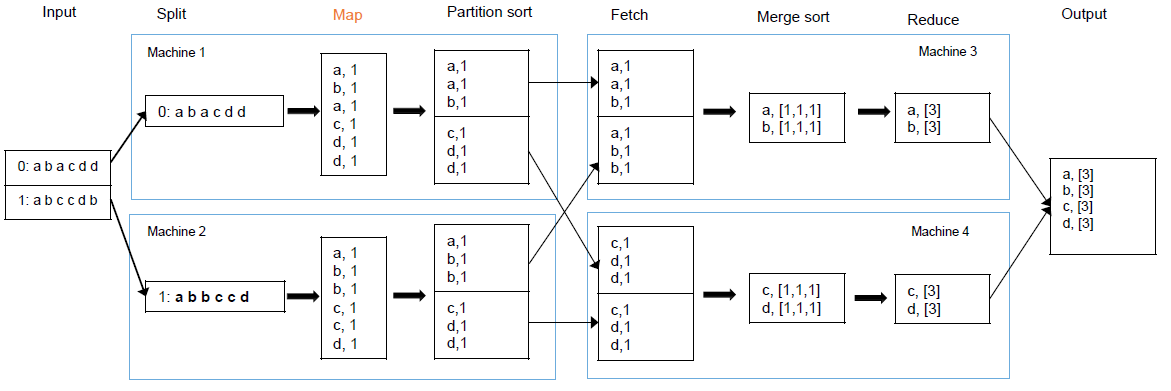
Anagram
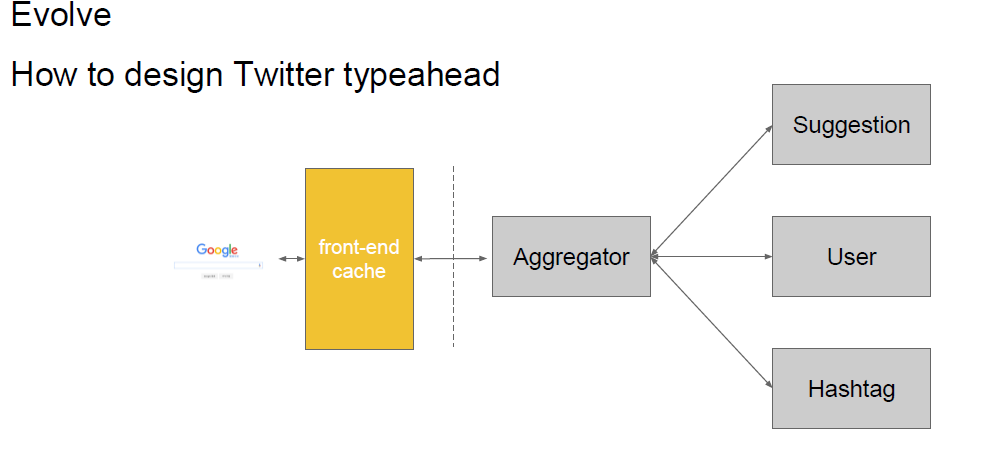
2 Typeahead